- psychology
ツァイガルニク効果
ツァイガルニク効果、というのを知った。
そもそもポモドーロテクニックを少し頑張ってやってみようかなと思い立ち、「ポモドーロの作業の区切り」というのはいつのがいいのかなと思って調べてみると出てきた。ポモドーロは関係ない言葉ではある。
人は、未完了のタスクの方を完了したタスクよりもよく記憶し、頭の中で持続的に意識し続ける
という感じの心理的効果のことを呼ぶ。
簡単に言えば、手を少しだけつけた仕事のほうが記憶力が上がるっぽい。逆にこれをうまく戦略として活用して、ポモドーロの区切りに「次のタスクをちょっとだけやる」「タスクの完了前にちょっと手を止める」みたいな方向性があるんだなと。
人間としては「キリのいいところまで終わらせる」方が当然いいような気もするが、あえてキリの悪いところで切り上げるという方向性で、ちょっとポモドーロを頑張ってみたい。 - architecture
イベントドリブンなアーキテクチャのパターン
最近 microservices architectureのパターンを知った。マイクロサービスに関するパターンが網羅されていてこういう名前がついているんだ、ということが知れた。
RDBMSとCloud Tasksを組み合わせて使うことが多いので
あたりは初めて知ったので、活用できそうだなと思ったのでメモ。まぁ考えれば結局この結論になりそうだが…。
Transactional outbox
一般的にRDBMSに何らかのデータを作成し、メッセージブローカー(例えばCloud TasksやPub/Sub、SQSとか)にメッセージを送信するのがマイクロサービスの基本(マイクロサービス自体は詳しくないが)。めっちゃ簡潔に書くなら下記だろう。
await db.transaction(async (tx) => { const order = await tx.createOrder({...}); }); await sendMessage(order);sendMessageはトランザクションがコミットされた後、つまりDBに更新がかかった後にメッセージを送信する。しかし、sendMessageが失敗した場合、トランザクションはロールバックされない。つまり、DBにはデータが残っているのにメッセージは送信されていない状態になる。これを解消するためにトランザクションの中でメッセージを送信するケースを考える。
await db.transaction(async (tx) => { const order = await tx.createOrder({...}); await sendMessage(order); });sendMessageはトランザクションの中で実行されるため、sendMessage終了後、今回の例ではトランザクションのコミットに失敗した場合、メッセージが送信されたのにも関わらずDBにはデータが残っていない状態になる。より複雑なトランザクションであればメッセージ送信後に処理を行う必要があるかも知れない。そうなるとメッセージを送信したのにROLLBACKされている可能性はある。
これを解消するのがTransactional outboxパターンである。トランザクションの中でメッセージを送信するのではなく、トランザクションの中でメッセージをDBに保存する。トランザクションがコミットされた後、別のプロセスがメッセージを送信する。
await db.transaction(async (tx) => { const order = await tx.createOrder({...}); await tx.saveMessage(order); });別サービスでは下記のような処理が何らかのスケジューラー等で実行される。
const messages = await db.getMessages(); for (const message of messages) { await sendMessage(message); await db.deleteMessage(message); }このようにすることで、DBのデータとメッセージングをアトミックにできる。
Idempotent consumer
Idempotent consumerは、メッセージを受信した際に同じメッセージを何度も受信しても問題ないようにするパターンである。特にCloud TasksやPub/Sub、SQSのサービスは"least once"の保証をしている(Pub/SubやSQSはexactly onceもあるらしいが)。逆に言えば同じリクエストがに2回発行されることもあるわけで、これを考慮する必要がある。
解決方法はシンプルで、処理開始時にDBに何らかのIDを保存しておく。処理が終わった後、DBからIDを削除する。次回同じメッセージが来た場合、DBにIDが存在するか確認し、存在した場合は処理をスキップする。
const id = requestBody.id; const rowsAffected = await db.execQuery( 'INSERT INTO processed_messages (id) VALUES (?) ON CONFLICT DO NOTHING', [id], ); if(rowsAffected === 0) { // メッセージはすでに処理済みなのでスキップ return; } // 処理を行う await db.execQuery('DELETE FROM processed_messages WHERE id = ?', [id]);ここではDBを用いているが、Redisの
NXオプションを使うなりすることでも解決可能だ。色々な記事を漁ると、最後にDELETEを入れない場合が多いが、Cloud Tasksのようにメッセージを再送信する場合は消すか、もしくはCloud Tasksから渡されるリトライカウントなどもキーに入れて保存するなどが必要になるかも知れない。
- GitHub, Markdown
GitHubのmarkdownでdiffを表示する
GitHubでコードブロックに
diffを指定すると、差分表示ができる。```diff none - minus + plus ```
GitHubのドキュメントにあるコードブロックの作成と強調表示ではlinguistを用いて言語判定しているとのこと。言語一覧にdiffがあるので、diffを指定すると差分表示になる。実際のハイライトはおそらくRougeを利用している?
1618 1619 1620 1621 1622 1623 1624 1625 1626 1627 1628 1629Diff: type: data extensions: - ".diff" - ".patch" aliases: - udiff tm_scope: source.diff ace_mode: diff codemirror_mode: diff codemirror_mime_type: text/x-diff language_id: 88 - metrics
RICEメトリクス
TODO
- react
server-only パッケージをインポートしたやつをどうにかして動かす
ReactやNext.jsにおいて、
server-onlyというパッケージをimportすることで、該当のパッケージをインポートした処理はServer側の処理からのみインポート可能になります。つまりuse clientなどをつけたコンポーネントからは利用できません。逆にclient-onlyというのもありますね。詳細はNext.jsの記事などが参照になります。例えばなのですが運用で使うスクリプトを実行する時に、
server-onlyパッケージをインポートしているライブラリが依存に入ってしまっていると、下記のエラーが発生してしまいます。これをどうにかしようという話です。Error: This module cannot be imported from a Client Component module. It should only be used from a Server Component.結論からすると
nodeに--conditions=react-serverというオプションを付与して実行することで解決します。node以外で実行する場合、例えばtsx等の場合はNODE_OPTIONS='--conditions=react-server'などで代替可能です。深堀り
server-onlyの仕組みは下記の記事が詳しいです。
https://quramy.medium.com/server-component-と-client-component-で依存モジュールを切り替える-7d65c8b2074f
重要なのはnodeのsubpath importsという機能です。その中でもConditional exportsという機能が重要です。
server-onlyのpackage.jsonを見ると下記のような定義がされています。server-only自体はGitHubで見つからないので、node_modulesの中から引っ張ってきています。{ // ... "exports": { ".": { "react-server": "./empty.js", "default": "./index.js" } } }defaultというのは条件に引っかからなかった時のデフォルトの挙動です。つまりreact-serverという何らかしらの条件に引っかかる場合はempty.jsが、そうではない場合はdefaultが呼ばれます。
ちなみにempty.jsは文字通り空っぽで、index.jsはエラーを吐くだけのファイルです。empty.jsindex.jsthrow new Error( "This module cannot be imported from a Client Component module. " + "It should only be used from a Server Component." );上記を見るに、
react-serverという条件であれば問題なくインポートできるようです。この条件を指定するのが--conditionsオプションです。node --conditions=react-serverのようなコマンドを打つことで、server-onlyの挙動を変更でき、動かすことが可能です。 - html
iframeに直接htmlを渡す
受け取ったHTMLメールをReactで作ったアプリで表示したい欲求が有りました。受け取ったHTMLしか表示しないので、最悪
dangerouslySetInnerHTMLでもいいっちゃ良いんですが、流石に少しは安全に倒したい。ということで、iframeのsandboxを利用したいなと思いました。が、iframeはsrcにhtmlのリンクを渡す必要があり、React上で管理しているHTMLの文字列を渡す方法はねぇかなと思いました。MDNを眺めてるとsrcdocという属性がありました。
インラインHTMLを埋め込み、srcの属性を上書きします。その内容は完全なHTMLドキュメントの構文に従う必要があります。※日本語のMDNだとなんか日本語がよくわからなかったので少し書き換えてます
HTMLをインラインで記載できるドンピシャのattributesがありました。下記のようにすればHTMLを表示しつつスクリプトの実行を抑制できます。
const HtmlMailPreview = () => { return <iframe srcDoc={'<h1>メールのタイトル</h1><script>alart("script!")</script>'} sandbox="" /> } - test
Vitestで「そのファイルに関連したテスト」を書く
タイトルの方法は
vitest relatedという命令により可能です(vitest relatedのドキュメント)。これはファイルを指定すると、そのファイルに関連したテストを実行するものです。ちなみにJestでは –findRelatedTestsというオプションで同様の動作ができます。関連というのはドキュメント上であまり明示されていませんが、基本的には該当のファイルをimportしたテスト、さらにimportした別のファイルをimportしたテスト、さらにimportしたやつをimportしたやつをimportしたテスト…みたいな感じで再帰的になんかいい感じに引っ張って来るようなイメージがあります。ですのでファイルによっては1ファイル指定しただけなのに何十ファイルもテスト対象になります。
例えば 派生元ブランチを取得するを利用すると、該当のブランチで編集したすべてのファイルに関連したテストを実行できます。
$ yarn test related --run $(git diff $(git show-branch | grep -e '*' -e '-' | grep -v -e '^\s*!' -e '^-' -e "$(git rev-parse --abbrev-ref HEAD)" | head -1 | awk -F'[]~^[]' '{print $2}') --name-only | grep -e '\.ts$') # aliasで派生元ブランチの取得を `git parent-branch` とするとスッキリします $ yarn test related $(git diff-file-from-parent | grep -e '\.ts$')ちなみにモノレポの場合、先頭に
packages/appみたいなパスが付与されているとファイルの指定がうまくいかないので、sedで編集するといいです。もしくはrootオプションを利用しても良いと思います。# aliasで派生元ブランチの取得を `git parent-branch` としています $ yarn test related $(git diff-file-from-parent | grep -e '\.ts$' | sed 's#^packages/app/##') - vscode
VSCodeでマークダウンを記載しているときに、コピペで画像を貼り付ける方法
VSCodeの2023-05の1.79のバージョンアップにて、マークダウンに画像などのメディアファイルを貼り付けられるようになったらしい。
画像や、画像ファイルをコピーした後Markdown上で貼り付けると
という形で文言が記載され、画像自体も同一ディレクトリの保存されるようになる。ディレクトリの保存先を変えるには下記のような設定を入れれば良い。下記は本ブログに関する設定だ。
settings.json"markdown.copyFiles.destination": { "/_data/**/*.md": "/_data/_images/${fileName}" },ちなみにすごいのが、シンボルの対応にも変更している点。画像のパス上で
Cmd-r(macOSのデフォルト、シンボルの名前変更機能)を行いファイルパスを変更すると、画像も自動的にそこへ移動する。そのため貼り付けた後に画像ファイル名を変更する際も楽ちんだ。 - git
派生元のブランチを取得する
Gitブランチの派生元・ベースブランチ・親ブランチ的なものを取得したくなることがあり、調べました。Gitで今のブランチの派生元ブランチを特定するなどで紹介されている方法があります。
$ git show-branch | grep '*' | grep -v "$(git rev-parse --abbrev-ref HEAD)" | head -1 | awk -F'[]~^[]' '{print $2}'ただ、私の環境ではそれだけでは動作しなかったので、以下のようにしました。
$ git show-branch | grep -e '*' -e '-' | grep -v -e '^\\s*!' -e '^-.*-$' -e "$(git rev-parse --abbrev-ref HEAD)" | head -1 | awk -F'[]~^[]' '{print $2}'変更点は真ん中の
grepのみです。深堀り
上記は結論ですが、どうしてこうなるかを説明します。
git show-branch
上記を深ぼるためにはgit show-branchの出力を知る必要があります。様々な記号がブランチ名とコミット名の先頭に付与します。
*は現在のブランチです。ブランチのHEADにつくのではなく、現在のブランチが持つ全てのコミットに付与されます-はマージコミットです。何故か*では無いです。これのせいでgrep '*'だけでは取得できません。特にmainブランチがマージコミットのみというプロジェクトもあるでしょう!は現在のブランチ以外のHEADコミットです。そのためこれを除外すれば自分のブランチのみを取得できます- 番外編として
---をご紹介。git show-branchの出力はHEADコミットとその親コミットの間に---が入ります
ドキュメントの例を見てみてもそんな感じです(ここにマージコミットの存在がありませんが)。
$ git show-branch master fixes mhf * [master] Add 'git show-branch'. ! [fixes] Introduce "reset type" flag to "git reset" ! [mhf] Allow "+remote:local" refspec to cause --force when fetching. --- + [mhf] Allow "+remote:local" refspec to cause --force when fetching. + [mhf~1] Use git-octopus when pulling more than one head. + [fixes] Introduce "reset type" flag to "git reset" + [mhf~2] "git fetch --force". + [mhf~3] Use .git/remote/origin, not .git/branches/origin. + [mhf~4] Make "git pull" and "git fetch" default to origin + [mhf~5] Infamous 'octopus merge' + [mhf~6] Retire git-parse-remote. + [mhf~7] Multi-head fetch. + [mhf~8] Start adding the $GIT_DIR/remotes/ support. *++ [master] Add 'git show-branch'.grep
git show-branchの説明を読めばgrepの意味は大抵わかります。
大元では
*を含むもののみとしていましたが、そうするとマージコミットが含まれませんので、-も含めるようにしました。
ただ、gitのブランチ名などでは-は一般的に利用されるため、先頭の自分以外のコミットなどが含まれてしまいます。そのため、"\\s*!の正規表現により除外するようにしました。
またはHEADコミットとその親コミットの間に---が入りますが、-の行を含むようになったためにこの邪魔な分割線も含まれるようになったため、'^-.*-$'によってこれも除外するようにしました。ちなみに^-+$でやってみたらなんか動かなかったのでこうしてます。
大本にもありますが、git rev-parse --abbrev-ref HEADによって現在のブランチを取得し、それを除外することを行っています。現在のブランチを取得する方法はget current branch nameという記事に何個か載ってます。これにより一番上に存在するのは「自分の持つコミットの中で、自分しか持っていないコミットを除いた一番上のコミット」になります。コレを派生元ブランチとしているわけですね。
head -1で一番上の行を取得するので、後はそこからブランチ名を取得するだけです。awk
awk以外の方法もあると思いますが、大元がそうしているんでその方法に倣ってます。正直
awkは雰囲気で使っていたので、何故awk -F'[]~^[]' '{print $2}'みたいに[]を2つ使っているのかわからなかったです。諸々調べると-Fは正規表現が指定できるらしいですね。なので、一見[]が2つあるように見えますが、実際には[]^~のうちどれかの文字、というのを表すために利用しているようです。[][~^]と書いても同じです。 - PostgreSQL
PostgreSQLのJSON配列に要素を追加する方法
PostgreSQLはカラムにJSONが使えます(まぁ、最近のSQLはだいたいサポートしているが)。JSONの特定の要素が配列で、その配列にデータを追加する際、なんか変なクエリ書くだけでJSONのそれ以外の部分が消えてしまうおそれがあります。
例えば下記のようなJSONが
jsonカラムにあるとします。{ "str": "data", "obj": { "key": "value" }, "array": [{ "elm": "1" }, { "elm": "2" }] }この時、
arrayに{ "elm": "3" }を末尾に追加するクエリは下記のようになります。UPDATE table_name SET json = JSON_SET( json, '{array}', COALESCE(json->'array', '[]'::JSON) || '[{"elm": "3"}]'::JSON ) WHERE id = 1;JSON_SETの代わりに||を利用することでも似たような感じの動作になります。UPDATE table_name SET json = json || json_build_object('array', COALESCE(json->'array', '[]'::JSON) || '[{"elm": "3"}]'::JSON) WHERE id = 1;||は配列の結合演算子で、COALESCE(json->'array', '[]'::JSONB)はjsonのarrayが存在しない場合に空の配列を返すための処理です。JSONBの場合はJSONB用の演算子があるので、JSON_の部分をJSONB_にすればだいたい動きます。
- eslint
ESLintでコメントを取得する方法
useEffectに必ずコメントを付与しよう、という文脈で下記の投稿を見ました。Lintにしてしまうのが良さそうと思ったのでhttps://t.co/iQROX8PuAS
— azu (@azu_re) January 30, 2025
適当に書いた。
useEffectにはコメントをつけよう - Panda Noirhttps://t.co/Ls4cx7i4IGESLintで扱うASTの大元となるESTreeではコメント関連のASTは定義されていない…と思います。そのため、上記を達成するために何をやっているのか気になりました。上記のgistのコードを読めば一目瞭然で、getCommentsBeforeメソッドを利用して取得可能なようでした。
このcontextは結構いろいろなメソッドを用意しているようで、祖先を取得できるgetAncestors(そういや使った記憶があるな)とか色々利用できそうですね。 - SQL
LATERALを使ったクエリ
SQLのLATERALというのを知りました。個人的な理解としては効率的なCROSS JOIN、N+1クエリのSQL版といった感じです(N+1に関してはJOINしてればだいたいそうだが)。LATERALはサブクエリの中で外側のクエリの値を参照できるという特徴があります。
具体例として下記のようなテーブルを考えてみます。アンケートと、その回答を格納するテーブルです。以降PostgreSQLを前提としています。
CREATE TABLE surveys ( survey_id bigint primary key, first_served_campaign bool ); CREATE TABLE answers ( answer_id bigint primary key, survey_id bigint, user_id bigint, answered_at timestamptz );ここで、アンケートに回答したユーザーの中で、先着3名までにプレゼントをする企画があったとします。
first_served_campaignカラムがtrueの場合、そのアンケートが対象となります。このとき、先着3名のユーザーを取得するクエリを考えます。パッと思いつくのがウィンドウ関数を用いる関数です。
WITH filtered_surveys AS ( SELECT survey_id FROM surveys WHERE first_served_campaign = true ), ranked_answers AS ( SELECT fs.survey_id, a.user_id, a.answered_at, ROW_NUMBER() OVER (PARTITION BY fs.survey_id ORDER BY a.answered_at) AS rank FROM filtered_surveys fs JOIN answers a ON fs.survey_id = a.survey_id ) SELECT survey_id, user_id FROM ranked_answers WHERE rank <= 3 ORDER BY survey_id;ただ、このクエリ、ちょっと遅い。
ranked_answersで全ての回答を取得してから、その中から先着3名を取得しているためです。ここでLATERALを使うと、サブクエリの中で外側のクエリの値を参照できるため、効率的に取得できます。SELECT s.survey_id, a.user_id FROM surveys s, LATERAL ( SELECT user_id FROM answers WHERE answers.survey_id = s.survey_id ORDER BY answered_at LIMIT 3 ) a WHERE s.first_served_campaign = true ORDER BY s.survey_id;first_served_campaignがtrueなアンケートが5,000件、回答がそれぞれアンケート毎に10,000件つまり合わせて回答が合わせて50,000,000件ある場合、前者のクエリは50,000,000件の回答を取得してから先着3名を取得しますが、後者のクエリはアンケート毎に3名の回答を取得するため、つまり15,000件の回答を取得するだけで済みます。実際、実行計画を見ると、前者のクエリはGather Mergeが50,000,000行に対して、後者のクエリはNested Loopが15,000行に対して行わるような計画になっています。結果コストが圧倒的に変わります。 - PostgreSQL
Docker上でPostgreSQLの拡張機能(pg_cron)を有効化する
先日pg_cronを知りました。で、こいつを開発環境のPostgreSQLに入れようと考えました。正直こいつを開発環境にいれるのは不要だと思いますが、他に開発環境でも使いたい拡張が現れたときに対応できるよう、試しに開発環境で有効化する方法を調べました。まぁあんまり開発環境のDocker上で拡張を有効化している人いませんでしたが。
pg_cronを追加すると仮定すると、下記のようなDockerfileで対応可能です。ちなみに15を使っている理由は開発開始時にAlloyDBが16をサポートしていなかったからです。今は16もサポートしています。
FROM postgres:15 RUN apt-get update && apt-get -y install postgresql-15-cron COPY ./entrypoint-pg-cron.sql /docker-entrypoint-initdb.d CMD ["postgres", "-c", "shared_preload_libraries=pg_cron", "-c", "cron.database_name=development"]同一ディレクトリに下記のファイルを追加します。
entrypoint-pg-cron.sqlCREATE EXTENSION IF NOT EXISTS pg_cron;docker-comoseを利用する場合も、通常のイメージを置き換える形で問題ないです。compose.ymlservices: db: # image: postgres:15 build: context: . environment: POSTGRES_USER: postgres POSTGRES_PASSWORD: postgres POSTGRES_DB: development ports: - 5432:5432 volumes: - db_volume:/var/lib/postgresql/dataDockerfileについての解説です。
postgresql-15-cronのインストールはpg_cronのインストール方法に従っているだけです。ちなみにPostgreSQLのイメージはdebian:bookworm-slimがベースになっているので、Debianベースのインストールです。/docker-entrypoint-initdb.dはPostgreSQLのDockerにてデータベースを立ち上げてから実行されるSQLまたはシェルスクリプトを配置するディレクトリです。ここにcreate extensionをするSQLを配置しています。
注意点として、こちらのスクリプトはすでにデータベースが構築されていると動作しません。永続化しているvolumeなどですでにデータベースが構築されている場合はdocker compose down -vとかdocker volume rmとかで該当のボリュームを削除してください。最後に
CMDを拡張しています。本来のCMDはpostgres1つだけなので、オプションをくっつけたい場合はただ増やせばいいだけです。
confファイルを更新する方法も合ったんですが、ファイルを用意したりする必要があるので見送りました。オプションの内容はセッティングに記載されています。timezoneを指定する場合はここに追加します。調査の際に参考にしたのは下記の記事です。
- PostgreSQL
pg_cronで定期的にデータを削除する
pg_cronはその名の通り、PostgreSQL上でcronベースのジョブスケージュールを行う拡張です。ちなみにMySQLではちゃんと調べていないですがイベントスケジューラというものが標準で搭載されているらしいです。
コレを使えば定期的にデータを削除できます。例えば、ログテーブルの古いデータを削除するとか。
今回はGoogle CloudのAlloy DBを使う前提です。使用可能拡張のページがあり、そこをみると問題なく利用できます。設定が必要で、
alloydb.enable_pg_cronを有効にする必要があります。設定変更のために20分ぐらいのダウンタイムが生じます。またこれはpg_cron側の設定ですが、cron.database_nameでデータベースを、cron.timezoneでタイムゾーンを変更できます。あとはpg_cronの公式ドキュメント通りに対応すればよいです。
-- 00:00(JST) SELECT cron.schedule('auth-delete-logs', '0 15 * * *', $$DELETE FROM logs WHERE created_at < now() - interval '90 days'$$); -- 削除するときは下記 -- SELECT cron.unschedule('auth-delete-logs');ログはできればCloud Logging使ったほうがいいと思う。
- Electron
Playwrightで動かすElectron上でipc通信を発火する
PlaywrightではElectronの自動化を(実験的ながら)サポートしています。Playwright、Electron単体でもとっつきづらいのに、その2つが組み合わされば特級呪物になりそうな気がします。Smokeテスト程度であればよさそうかもしれません。
Electronは大雑把に言うとmainプロセスとrendererプロセスがあります。rendererプロセスは通常のブラウザです。例えばファイルの読み取り・更新をしたいときなどはnode.jsであるmainプロセスにIPC通信することで実現します。逆も同様で、mainプロセスで何らかのイベント、特定のファイルが更新された場合などにrendererプロセスにIPC通信することでファイルの変更をブラウザに反映させることができます。
テストを実施するときに、例えばどうしてもmain → rendererプロセスの通信の発火条件を満たせないケースがあったとします。ここでは特定のファイルが更新された場合、という条件とします(それぐらいなら頑張って発火できると思いますが)。このときにrendererプロセスに対してIPC通信でデータを送信する方法です。
下記が基本形です。
const { _electron: electron } = require('playwright'); (async () => { const electronApp = await electron.launch({ args: ['main.js'] }); const electronPage = await electronApp.firstWindow(); })();ここで重要なのは
electronAppがmainプロセス、electronPageがrendererプロセスに紐づいていることです。今回はmain → rendererの通信ですので、electronPageでデータをsendします。
具体的にはevaluateメソッドを利用します。await electronApp.evaluate(async (app) => { // NOTE: ウィンドウIDは起動時からインクリメントされるため、最初に開いたウィンドウである1を指定している const focusedWindow = app.BrowserWindow.fromId(1); focusedWindow?.webContents.send("changeConfigFile", { config: { hoge: "fuga", } }); });上記のようにすることでデータを送信できます。が、残念ながらwindowのIDを取得できないため、そこは固定値にするしか現状は無いと思われます。幸いなことにElectronのwindowのIDは1からインクリメンタルされる数字なので特定は容易いです。
- Google Cloud
permissions.cloudがCloudのIAMの権限を見るのに便利
permissions.cloudはクラウドの権限周りを確認できるサイトです。
Cloud Runにおける権限変更に合わせて、既存のIAMが問題ないかを確認するために利用しました。
現在のCloud Runのデプロイするサービスアカウントは
roles/artifactregistry.writerを持っていましたが、このroleで問題ないか、roles/artifactregistry.readerを付与する必要があるかを確認したかったです。が、Google Cloudのドキュメント上にはroleの持つ権限が記載がなかったですが、上記サイトにて記載されていました。
roles/artifactregistry.writerの権限を確認し、roles/artifactregistry.readerの権限をすべて持っていることを確認しました。ドキュメントに記載されていない権限が出てくるの良いですね。データセットの元はiam-datasetというリポジトリであり、中身を見るとクローラーで収集しているっぽいです。その元データはIAM permissions referenceというデータでした。こんなページあったんですね。超重いので、permissions.cloudを活用していきたいと思います。
- 心理学
特殊的好奇心と好奇心の尺度
特殊的好奇心という言葉を知った。
これは心理学者のBerlyneの「Conflict, arousal, and curiosity」によって提唱された概念である。本を読んだわけだわけではないが、調べてみると 知的好奇心尺度の作成 [1]という論文を見つけ、様々な知らない世界があったのでメモ。
Berlyne氏は好奇心には2つあり、知的好奇心と知覚好奇心とした。知覚好奇心は聴覚・触覚・味覚・嗅覚・視覚の身体的感覚の新規性を求めることである。知的好奇心はさらに2つあり、拡散的好奇心と特殊的好奇心があるとした。 知的好奇心尺度の作成 では拡散的好奇心は新奇の情報を探し求めることを動機付け、特殊的好奇心はズレや矛盾などの認知的な不一致を解消するために特定の情報を探し求め続けることを動機付ける、としている。論文内の例として、拡散的好奇心はたまたま推理小説を手に取り読むこと、特殊的好奇心は推理小説の内容を理解するまで何度も読むことが挙げられている。
論文は尺度を作るための2つの研究からなっていて、1つは12個の設問により拡散的好奇心と特殊的好奇心の尺度を作成し、もう1つはいくつかの他の尺度と比較して妥当性を検証している。比較対象の尺度も面白かったので紹介してみる。
- Big Five尺度:利用しているのはBig Five尺度短縮版[2]である。人のパーソナリティを5つの要素に分類する Five Factor Model では、外向性、協調性、誠実性、神経症的傾向、開放性がある。これらを形容詞を利用して評価するのがBig Five尺度であり、オリジナルより少ない設問数で評価できる短縮版もある。外向性は名前の通り外交的な人間かどうか。協調性・誠実性も同様に文字通り。神経的症傾向は緊張やストレスへの耐性。開放性が好奇心に強く結ばれており、この尺度が高いと新しいアイデアや既存にとらわれない考えができるとされている。
- BIS/BAS尺度:人の動機付けを評価する尺度であり、 BIS(Behavioral Inhibition System)は罰を避ける動機付け、BAS(Behavioral Activation System)は報酬を求める動機付けを評価する。BASにはさらに3つの要素があり、それぞれ駆動・刺激探求・報酬反応性とされている。駆動は報酬のために行動する・刺激探求は報酬がありそうならやってみる・報酬反応性は報酬があるなら興奮するといった感じの理解をしている。
- 話はそれるがBIS/BAS が意思決定フレーミング効果に及ぼす影響という論文も面白かった。
- 認知的完結欲求尺度:問題に対する回答に曖昧さを嫌い完結さを欲求する尺度である。心理テストとかで時折出てくる「決断するのに苦労する・時間をかける」(Yesだと低い)や「重要な決断を素早くできる」などに代表される決断性、「規則正しい生活が合っている」などの秩序(完璧に私は秩序がない人間だ)、「何がわからない状況だとワクワクする」(Yesだと低い、私は100%Yesである)や「何やるかわからない人とは行動したくない」などの「予測可能性」の3つの尺度がある。
- 認知的欲求尺度:簡単に言えば「頭を使うのが好き」とか「必要以上に課題に対して考えてしまう」などによって評価する。私は100%Yesである。
- 曖昧さへの態度尺度:曖昧さにたいしてYes/Noという単純な尺度ではなく、さらに享受・受容・統制・排除・不安という5つの要素に分離した尺度。享受は曖昧であると全部試したい/想像する。受容は曖昧であることを良しとする。統制は曖昧な情報の確度を高める。排除は曖昧な状態が嫌いである。不安は曖昧な状態から遠ざかりたい。似ている感じもするがこの5つは独立している尺度らしい。
知的好奇心尺度の作成では3つの仮説を立てている。
- 拡散的好奇心・特殊的好奇心には知的好奇心としての共通性がある。具体的には「開放性尺度」、「BAS駆動尺度」、「認知的欲求尺度」との関連が高い
- 特殊的好奇心は拡散的好奇心に比べ「認知的完結欲求尺度」「曖昧さへの統制尺度」「曖昧さへの排除尺度」「曖昧さへの不安尺度」との関連が高い
- 拡散的好奇心は特殊的好奇心に比べ「BAS刺激探求尺度」「曖昧さへの享受」「曖昧さへの受容」との関連が高い
全てが一致しているわけではない(特に知的好奇心がある人間は曖昧さへの否定的態度を取るため)が、概ね仮説通りという感じの結果だった。
今回知った尺度を個人に投影すると面白い。私としては知的好奇心はある方だと思っているが、今回の指標全体的に拡散的好奇心・特殊的好奇心両方の側面もありそうでこういった尺度に裏付けされることがわかる。しかし「認知的完結欲求尺度」はいずれも当てはまっていない。これはこの世界には未知しか存在しないからこそ未知に出会える環境にワクワクしているというある意味で好奇心のようなものかなと。
西川一二, 雨宮俊彦. 知的好奇心尺度の作成 - 拡散的好奇心と特殊的好奇心. 教育心理学研究. 2015. 63巻. p412-425. https://www.jstage.jst.go.jp/article/jjep/63/4/63_412/_pdf ↩︎
並川努, 谷伊織, 脇田貴文, 熊谷龍一, 中根愛, 野口裕之. Big Five尺度短縮版の開発と信頼性と妥当性の検討. 心理学研究. 2012. 83巻2号. p91-99. https://www.jstage.jst.go.jp/article/jjpsy/83/2/83_91/_pdf ↩︎
- Electron
XvfbによるElectronのヘッドレス化(Playwright × ElectronをDocker上で動かす)
Electronにはヘッドレスモードはない。そのため、GUIの無いシステムではElectronを使うこともできないわけで。たいてい問題はないが、つまりDocker上で動かすことができないということになる。
XvfbはX Virtual FrameBufferのことで、X Window Systemの仮想ディスプレイのサーバーである。これを使うことでElectronをヘッドレスモードで動かすことができる。下記のドキュメントを参照。
https://www.electronjs.org/ja/docs/latest/tutorial/testing-on-headless-ci
具体的にPlaywright × ElectronをDocker上で動かせるようにしたいときに使える。下記はDockerfileの例(
yarn e2eでPlaywrightのテストを実行することを想定している)。FROM mcr.microsoft.com/playwright:latest@ WORKDIR /app RUN apt-get install -y xvfb RUN npm uninstall -g yarn \ && rm -rf /usr/local/bin/yarn /usr/local/bin/yarnpkg COPY ./package.json ./package.json RUN corepack enable \ && corepack install RUN yarn install --immutable RUN yarn playwright install chromium COPY . . CMD ["xvfb-run", "yarn", "e2e"]注意するべきはこれだと動かない場合がある。というのもDockerの実行プロセスがPID 1で動いておりシグナルハンドルが出来ないから…だと思う。–initオプションを付与すると動くようになるので、多分そうだと思う。
後もう1つ、大抵の場合はWindowsで動かす場合が多いので、お手持ちのCIのWindows環境で動かすほうがいいと思う。Github Actionsであればwindows環境がある。
- javascript
package.jsonのdependenciesのバージョンをpinするシェルスクリプト
Renovateでは依存関係をpinすることを推奨していますし、yarnではdefaultSemverRangePrefixによりデフォルトでバージョンを固定化出来ます。
しかしこういった設定をする前にあれこれインストールしてしまって、後からpinするの、ちょっと面倒ですよね。renovateが勝手にやってくれるはずなんですが、なんかやってくれないし。
下記はそれをやってくれるスクリプトです。#!/bin/bash while read -r package current_version; do latest_version=$(yarn info "$package" version --json | jq -r '.children.Version') jq --arg package "$package" --arg latest_version "$latest_version" '.dependencies[$package] = $latest_version' package.json > tmp.json && mv tmp.json package.json done < <(jq -r '.dependencies | to_entries[] | "\(.key) \(.value)"' package.json)注意点として下記があります。
jqが必要ですdependenciesを対象としています- 2行目・4行目の
dependenciesをdevDependenciesに書き換えればdevDependenciesを対象に出来ます
- 2行目・4行目の
yarnを利用していますpnpmの場合はlistが使えると思います- その場合2行目の
jqのコマンドもおそらく変える必要があります
- Next.js
Next.jsでビルド中かどうかを判定する(Next.jsのビルド時だけエラーになる処理に対する対応)
NEXT_PHASEという環境変数を利用することで判定できます。またはNEXT_IS_EXPORT_WORKERでも判定可能です。背景
下記のような、
環境変数がなかったらエラーになる処理を書こうとします。config.tsconst fetchEnv = (key: string): string => { const value = process.env[key]; if (!value) { throw new Error(`環境変数 ${key} が設定されていません`); } return value; } export const OIDC_ISSUER = fetchEnv('OIDC_ISSUER');この処理を、例えば
app/api/auth/login.ts等で下記のように記載するとします。app/api/auth/login.tsimport { OIDC_ISSUER } from "@/config"; const issuer = new Issuer({ issuer: OIDC_ISSUER, // ... }); export function GET() { // ... } export const dynamic = "force-dynamic";動的なページであれば、実行環境の環境変数が利用されるのでビルド時には本来不要です。そのためDockerなどでビルドするときも環境変数は不要なはずです。
一方で上記の状態でビルドを行うと、Next.jsのビルド時に実際のコードが読み込まれ、fetchEnv("OIDC_ISSUER")が実行されます。理由
理由としてはNext.jsのビルド、特にApp Routerを有効化している際には
exportという処理が走るからです。exportは簡単に言えば静的なページを作成するための処理です。App Routerで常に実行されるのは、App Routerのデフォルトの挙動が静的なページを生成するためのものだからと想像しています。静的なページを作成するためには当然対象のページのコードを読み込む必要があります。その際に上記のコードであれば
fetchEnv関数の実行まで始まってしまうため、環境変数がない場合はエラーになってしまいます。対応方法としてはいくつか考えられそうです。
fetchEnvをビルド時に実行しないようにする例えば環境変数を定数ではなく関数にするとか。
config.tsconst fetchEnv = (key: string): string => { const value = process.env[key]; if (!value) { throw new Error(`環境変数 ${key} が設定されていません`); } return value; } export const getOidcIssuer = () => fetchEnv('OIDC_ISSUER');Dynamic Importにするとか。
app/api/auth/login.tsexport async function GET() { const { OIDC_ISSUER } = await import('@/config'); const issuer = new Issuer({ issuer: OIDC_ISSUER, // ... }); } export const dynamic = "force-dynamic";やりたいことに対して対応が大きすぎる気もする。
const lazyが欲しいですね。ビルド時のみエラーにならないようにする
Next.jsでビルド中かどうかを判定するために環境変数が存在します。それが
NEXT_PHASEです。NEXT_PHASEについて示唆されているDiscussionが一番詳細に記載されています。
NEXT_PHASEの値の定義として下記の5つの値が存在します。上記で
export時に実行されると記載されていますが、NEXT_PHASEはphase-exportではなくphase-production-buildとなっていることに注意です。export const PHASE_EXPORT = 'phase-export' export const PHASE_PRODUCTION_BUILD = 'phase-production-build' export const PHASE_PRODUCTION_SERVER = 'phase-production-server' export const PHASE_DEVELOPMENT_SERVER = 'phase-development-server' export const PHASE_TEST = 'phase-test'また、それだとビルド中なのかExport中なのか判断がつかないため、
NEXT_IS_EXPORT_WORKERという環境変数も存在します。trueという値が入ります。下記のように環境変数を利用してビルド時のみエラーにならないようにできます。
config.tsimport { PHASE_PRODUCTION_BUILD } from "next/dist/shared/lib/constants"; const fetchEnv = (key: string): string => { const value = process.env[key]; if (!value) { if (process.env.NEXT_PHASE === PHASE_PRODUCTION_BUILD) { return ""; } throw new Error(`Missing environment variable: ${key}`); } return value; }; export const OIDC_ISSUER = fetchEnv('OIDC_ISSUER'); - docker
DockerでCOPYを用いずにpackage.jsonを使ってyarn installする(RUN実行時に一時的にマウントする)
Dockerについて半日ぐらい調べたときの成果2。
RUN --mountについて。COPYコマンドは最終成果物に含まる。例えば、
COPY . .で全てのファイルをコピーすると、最終成果物には全てのファイルが含まる。これは不要なファイルが含まれるため、最終成果物のサイズが大きくなる。マルチビルドステージにより解決できるが、それ以外にもRUN --mountを使うことで解決可能だ。
基本的には公式ドキュメント通りだが、下記のようにすると、pakage.jsonを成果物に含めずにyarn installが可能だ。FROM node:22 AS build RUN yarn installただし
--mountとCOPYで大きく違うところが1つあり、既存のディレクトリをtargetとしたときの挙動である。
COPYはリファレンス内にて下記のように記載されている。If it contains subdirectories, these are also copied, and merged with any existing directories at the destination. Any conflicts are resolved in favor of the content being added, on a file-by-file basis,
サブディレクトリが含まれている場合、それらもコピーされ、コピー先の既存のディレクトリとマージされます。競合がある場合は、ファイルごとにコンテンツが追加されるように解決されます。
一方でRUN --mount、正確にはbind mountについてはリファレンスにて下記のように記載されている。
If you bind-mount a directory into a non-empty directory on the container, the directory’s existing contents are obscured by the bind mount.
コンテナ内の空でないディレクトリにディレクトリをバインドマウントすると、ディレクトリの既存の内容がバインドマウントによって隠されます。
つまり、COPYはディレクトリをマージするが、–mountはディレクトリを上書きするような挙動になる。
- docker
Dockerのマルチステージビルド
Dockerについて半日ぐらい調べたときの成果1。マルチステージビルドについて。
公式ドキュメント以上や、その他既にたくさんある記事以上の情報はないが、少なくとも令和のDockerfileでは必須な知識だと思う。
下記のように、FROMが2個以上出てくるのが特徴だ。例えばWebpackによりバンドルしたファイルをnodeで実行するときなんかにとても効力を発揮する。
FROM node:22 AS build WORKDIR /app COPY . . RUN npm install && npm run build FROM node:22 AS runtime WORKDIR /app COPY /app/dist /app/dist CMD ["node", "dist/index.js"]ステージというのは簡単に言えばFROMで定義したイメージのことで、上記ではビルドと実行の2つのステージがある。Dockerの最終的な成果物は最後のステージのイメージになる。この場合は
runtimeステージだ。
COPY --fromにより異なるステージの中で生成されたファイルをコピーできる。上記では最終的に実行に必要なバンドル後のapp/distディレクトリをruntimeステージにコピーしている。これの最大の利点は最終的な成果物のサイズが小さくなることだ。1つのステージしかなければ(明示的に削除しない限り)
node_modulesやsrcなど不要なファイルがふくまる。とくにnode_modulesなんかはデカくなりがちであるため、これを削除することでイメージのサイズを小さくできる。 - docker
Dockerでモノレポのpackage.jsonをいい感じにコピーする(ディレクトリ構造を維持しつつコピーする)
Dockerについて半日ぐらい調べたときの成果3。
COPY --parentsについて。モノレポ環境でDockerのビルドをしたい時に、
yarn installをしたい場合、2つほど問題が発生する。- 他パッケージに依存しているときはモノレポのルートでCOPYをする必要がある
yarn install --immutableをする場合は、すべてのモノレポのpackage.jsonが必要
上記を解決するためには、モノレポのルートをビルドコンテキストとして指定する必要がある。そこで各パッケージの
package.jsonをコピーしたいが、COPY ./packages/*/package.json .のようなコピーの方法は使えない。というのもこれだと./packages/backend/package.jsonを./package.jsonにコピーした後./packages/frontend/package.jsonを./package.jsonにコピーする、という感じの動作になる。つまり、最後にコピーしたpackage.jsonが残る。これを解決するのにはCOPY ./packages/backend/package.json ./packages/backend/package.jsonのように、コピー元とコピー先を指定する必要がある。これだとパッケージが増える度に指定する必要がある。そこで**COPY --parentsを利用する。これはコピー元の親ディレクトリを保持したままコピーしてくれる**、上記の課題を解決してくれるすぐものだ。
COPY --parents ./packages/*/package.json ./とやると、
./packages/backend/package.jsonを./packages/backend/package.jsonにコピーし、./packages/frontend/package.jsonを./packages/frontend/package.jsonにコピーする、という動作になる。ドキュメントに記載通りだが、上記はstableな機能ではないため、
# syntax=docker/dockerfile:1.7-labsを先頭に扶養する必要がある。 - vscode
もうAuto Rename Tagは不要だった
Auto Rename TagはVSCodeの著名な拡張の1つです。
上記拡張のNoteにも記載があるのですが、実はこの機能がVSCodeのビルトインとして統合されています。
デフォルトで有効化されていませんが
editor.linkedEditingという設定をtrueにすることで有効になります。 - sql
SQLのUPDATE RETURNINGで更新対象外のテーブルをJoinする
更新処理を実行した後、対象以外のテーブルをジョインしてRETURNINGして欲しくなった。
まぁ、これに関しては、実装的に1つのクエリでやりたいことが2つ出てしまうのであまり良くないと思ったので、結局は更新処理と取得処理を分離した。通信に関してあまり詳しくはないが、仮にトランザクション中であれば接続貼りっぱなしだと思うので通信のRTTも気にならんだろうし。
ただ、JOINしてWHEREしたいケースにも利用できる(というか、どちらかというとそちらがメイン)。FROM句を利用する。UPDATEにFROM句が使えるんだな。下記はPostgreSQLのリファレンスより引用し、RETURNINGを追加している。
UPDATE employees SET sales_count = sales_count + 1 FROM accounts WHERE accounts.name = 'Acme Corporation' AND employees.id = accounts.sales_person RETURNING employees *, accounts.*; - sql
PostgreSQLのSKIP LOCKED
PostgreSQLを利用して、キューのようなものを作成したくなったところ、SKIP LOCKEDというものを知りました。
名前の通り、ロックされている行ををスキップしてくれるものです。例えば下記のようなテーブルを作成してみます。
CREATE TABLE tasks ( id SERIAL PRIMARY KEY, status TEXT NOT NULL DEFAULT 'pending', created_at TIMESTAMPTZ NOT NULL DEFAULT CURRENT_TIMESTAMP ); INSERT INTO tasks (id) VALUES (1), (2), (3), (4), (5);現状こんな感じ。
$ select * from tasks; id | status | created_at ----+---------+------------------------------- 1 | pending | 2024-06-29 12:34:50.000000+00 2 | pending | 2024-06-29 12:34:51.000000+00 3 | pending | 2024-06-29 12:34:52.000000+00 4 | pending | 2024-06-29 12:34:53.000000+00 5 | pending | 2024-06-29 12:34:54.000000+00ここで、下記のようなトランザクションを実行します。まだコミットしていないので対象の行はロックされたままです。
$ BEGIN; $ SELECT id FROM tasks ORDER BY created_at LIMIT 1 FOR UPDATE; id ---- 1この間にトランザクション外から下記のコマンドを実行してみます。
$ SELECT id FROM tasks FOR UPDATE SKIP LOCKED; id ---- 2 3 4 5この様に、ロックされたid 1の行をスキップしました。
PostgreSQLのリファレンスにはSELECT - ロック処理句に記載があります。
こちらの機能はSQL標準ではないようですが、MySQLにも存在しています。おそらく8.0から。 - npm
npm scriptsで引数をいい感じに分割して複数コマンドに分配したい
タイトルからだとかなり読みづらいが、下記のようなことをしたい。こういった欲求は度々起こるが、その度調べては難しそうだったので諦めていた。簡単に言えばnpm scriptsの内部で引数を分離したいのである。
lint・prettierを一発でやるコマンド{ "scripts": { "lint:fix": "eslint --fix", "prettier:write": "prettier --write", "format": "???" }, }上記のスクリプトがある前提で、下記を期待する。
$ npm format __tests__/index.test.ts > npm lint:fix __tests__/index.test.ts && npm prettier:write __tests__/index.test.ts例えばシンプルに下記のようにする。
lint・prettierを一発でやるコマンド{ "scripts": { "lint:fix": "eslint --fix", "prettier:write": "prettier --write", "format": "npm lint:fix && npm prettier:write" }, }そうすると最後に引数がくっつくだけである。
$ npm format __tests__/index.test.ts > npm lint:fix && npm prettier:write __tests__/index.test.tsnpmだけではそういうことはできなさそう だが、ここでnpm-run-allの存在を思い出した。もう6年前から更新されてない。
結論としてはnpm-run-allで今回の欲求は満たせた。Argument placeholdersという機能を利用すれば良い。lint・prettierを一発でやるコマンド{ "scripts": { "lint:fix": "eslint --fix", "prettier:write": "prettier --write", "format": "run-s 'lint:fix {1}' 'npm prettier:write {1}' --" }, }$ npm format __tests__/index.test.ts > npm lint:fix __tests__/index.test.ts && npm prettier:write __tests__/index.test.ts最後の
--はscripts側にないと想定通りに動作にはならない。 - vscode
ESLintがCLIだと動くのにVSCodeだと動かない
下記の条件を満たしていると、VSCodeのバージョンが1.90.0(2024-06-12時点での最新)以下で動作しない。
- typescript-eslintを利用している
- monorepoを利用している
- ESMである・
eslint.config.mjsである languageOptions.parserOptionsのprojectおよびtsconfigRootDirを設定しているimport.meta.dirnameを利用している ← これが原因
原因としては、VSCode1.90.0の内部で利用されているElectron 29のNode.jsのバージョンが20.9.0であるため、
import.meta.dirnameが利用できない。
import.meta.urlは利用できるため、下記のような回避策で解決できる。eslint.config.jsonimport { fileURLToPath } from "url"; const filename = fileURLToPath(import.meta.url); const dirname = import.meta.dirname ?? path.dirname(filename); export default tseslint.config( ..., { languageOptions: { parserOptions: { project: ["./tsconfig.eslint.json", "./packages/*/tsconfig.json"], tsconfigRootDir: dirname, }, }, }, ..., )Node.js 20.11.0で追加されている ので、Electron v30(Node.js 20.11.1)では
import.meta.dirnameが利用可能になるはず。 - vscode
VSCodeでyamlを開いた際、候補を表示しない
yamlを編集していると候補が邪魔をしてきて鬱陶しかったので設定を入れた。
下記を記載すると、入力するだけで候補の表示がされなくなる。Macであればctrl-space(入力ソースの変換と被っているが)で候補は表示される。settings.json"[yaml]": { "editor.quickSuggestions": { "comments": "off", "strings": "off", "other": "off" } }P.S.
1回上記の設定を入れた後に無効化しても全然候補が表示されなくなった。今回参考にしたのは下記の記事。
- gcloud, solve
brew upgrade後gcloudコマンドが動かなくなった
brew upgrade後、
gcloudコマンドを叩くと下記のようなエラーが発生するようになった。ERROR: gcloud failed to load. This usually indicates corruption in your gcloud installation or problems with your Python interpreter. Please verify that the following is the path to a working Python 3.8-3.12 executable: /Users/sa2taka/.pyenv/versions/3.11.1/bin/python If it is not, please set the CLOUDSDK_PYTHON environment variable to point to a working Python executable. If you are still experiencing problems, please reinstall the Google Cloud CLI using the instructions here: https://cloud.google.com/sdk/docs/install Traceback (most recent call last): File "/Users/sa2taka/libs/google-cloud-sdk/lib/gcloud.py", line 106, in gcloud_exception_handler yield File "/Users/sa2taka/libs/google-cloud-sdk/lib/gcloud.py", line 183, in main gcloud_main = _import_gcloud_main() ^^^^^^^^^^^^^^^^^^^^^ ...(中略)... ImportError: dlopen(/Users/sa2taka/.pyenv/versions/3.11.1/lib/python3.11/lib-dynload/_ssl.cpython-311-darwin.so, 0x0002): Library not loaded: /usr/local/opt/[email protected]/lib/libssl.1.1.dylib Referenced from: <...> /Users/sa2taka/.pyenv/versions/3.11.1/lib/python3.11/lib-dynload/_ssl.cpython-311-darwin.so Reason: tried: '/usr/local/opt/[email protected]/lib/libssl.1.1.dylib' (no such file), '/System/Volumes/Preboot/Cryptexes/OS/usr/local/opt/[email protected]/lib/libssl.1.1.dylib' (no such file), '/usr/local/opt/[email protected]/lib/libssl.1.1.dylib' (no such file), '/usr/local/lib/libssl.1.1.dylib' (no such file), '/usr/lib/libssl.1.1.dylib' (no such file, not in dyld cache)エラーの上部に解決策が色々出てるが、原因は下部のほうにある
[email protected]がないことだ。どうやらbrew upgradeを叩いた際に消えたようだ。
とりあえず[email protected]をダウンロードすることで解決できる。$ brew install [email protected] - notion
Notionの引用のショートカット
一般的なマークダウンでは
>が引用であるが、Notionではトグルに割り当てられている。/quoteとすることで引用にできるが、それ以外に"または|がショートカットとして割り当てられている。確かに|は一般的な引用のスタイルだし、わかりやすいかもしれない。 - typescript,eslint
TypeScript ESLintがモノレポ環境でOOMになるのを解決
TypeScript ESLintはTypeScriptの型情報を利用して、よくあるミスを洗い出してくれるいい子ですが、そのかわり1回TypeScriptのパーサーを挟むので重い・遅い・メモリを食うという状況になります。
重すぎるので今までCI以外では切っていたんですが、Flat Config化するにあたり、せっかくなら普段のVSCode上でエラーも出したいしということでTypeScript ESLintを全体有効化したところ、設定が誤っていて今までモノレポ環境のLintでTypeScript関連のルールが動いていなかったことが判明。エラーが2つぐらいでるようになったのは良いのですが、何やったってCIがメモリエラーで死ぬ。何なら32GBある私のPCもメモリエラーが吐かれる。
下記のようなエラーですね。FATAL ERROR: Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap out of memory調べたところ、ちょうど今日解決策がissueに投稿されていました。
EXPERIMENTAL_useProjectServiceというプロパティを設定すればよいようです。flat configであれば下記のように
parserOptionsを設定しましょう。eslint.config.jsexport default [ { languageOptions: { parserOptions: { ..., EXPERIMENTAL_useProjectService: true, }, }, } ]EXPERIMENTAL_useProjectServiceは名前の通りまだexpreimentalな機能です。
TypeScript ESLintが重い理由はts.CreateProgramを利用しているからです(多分)。
で、上記を有効にすると、こんな感じでASTを取得します。useProgramFromProjectService.tsconst program = service .getDefaultProjectForFile(scriptInfo!.fileName, true)! .getLanguageService(/*ensureSynchronized*/ true) .getProgram();これがなぜ早くなるのか、正直全くわかりませんが実際にOOMが解決されるのでなにか意味があるのでしょう。
Copilot3.5では無理でしたが、Claudeで聞くといい感じに答えてくれます。全然情報が無いですね…。私のJS Test Outlineもts.Program利用しているので、ProjectServiceの利用を検討してみようかしら。
- git
Gitで最後に触っていたブランチに戻る
最近よく「一瞬だけこのブランチに移動して、その後もとに戻る」という操作をする。しかし、びっくりするぐらい短期力に難がある私にとって3分前に切り替えたブランチ名は忘れるのである。
調べると最後に触っているブランチへ戻る方法があった。$ git switch - # 上は下記の糖衣構文。-1の部分を2とか3とかにすればもっと遡れる。HEADみたいなもんすね $ git switch -@{-1}またreflogにもログが残っている。
$ git reflog | grep switch 12345abce HEAD@{0}: checkout: moving from master to release参考:
https://qiita.com/ginpei/items/2e0cd22df0670b3a1c3f
https://ginpen.com/2022/12/09/git-back-to-last-branch/
https://zenn.dev/yajamon/articles/422ecab49804f9 - raw
指標はハックされる〜グッドハートの法則
私は、何らかの人間に対する計測時にハックされる可能性を必ず考慮する。
例えば給料の査定(私自身にそんな権限はないが)だったりもそうだし、生産性を上げるときの計測対象なんかは最近専ら議論している。こういった話をした時にチームメンバーから教えていただいたのが、グッドハートの法則。
グッドハートの法則
グッドハートの法則は「指標が目標となると、それは良い指標ではなくなる」と説明されている。これだと、巷で噂のKPIは良い指標ではないのかと突っ込みたくはなるが、言いたいことはそうではないと思う。裏まで読むと「指標にすべきではない指標が目標となると、それは良い指標ではなくなる」、言ってしまえば目標とすべき指標はちゃんと選べよということかもしれない。
例えば、生産性の目標としてPR数を指標とした。PR数が上がれば生産性が上がったよねとする。そうなると、俺は通常より細かい単位でPRを作る。そうすれば生産性が上がるから。本当の目標は「生産性を上げる」なのに「PR数を作る」という、俗に言うと手段と目的が入れ替わっている状態となる。
これじゃ駄目だよねという話。
複数の指標を測る・加えて一部の指標を定性的な目標にする、等少なくともハックできないようなものにする。または、目的 = 指標(目的 ∈ 指標)となるような指標を選択することが回避に大切だと思う。
例えば生産性を測るためにFour Keysを利用する。この場合目的 = 指標とは言いづらいが、統計的に有為であるため問題はないといえる。
具体例としては コブラ効果 などもその例だろう。寓話っぽくて好き。
また、キャンベルの法則という似たような法則もある。
- unicode
Unicode正規化
言語処理の文脈で、度々Unicode正規化という言葉を聞く。言葉や処理自体は知っていたが、いくつか種類があるようなので改めて調べてみた。
Unicode正規化(ユニコードせいきか、英語: Unicode normalization)とは、等価な文字や文字の並びを統一的な内部表現に変換することでテキストの比較を容易にする、テキスト正規化処理の一種である。
具体的に、正規化には4種類ある。
- NFD
- NFC
- NFKD
- NFKC
末尾のD・CはそれぞれDecomposition(分割)・Composition(結合)である。Dの場合は正規化した上で分解したまま、Cの場合は分解した後結合する。
Kの有無だが、これは正準等価(K無し)・互換等価(K有り)の違いらしい。具体的には調べていないが、正準等価に比べ互換等価の方が緩く分解されるらしい。JavaScriptにおいては
Stringにnormalizeメソッドが生えているため、それを利用することでノーマライズが可能である。$ node > const char = "ギ" undefined > char.normalize("NFD") 'ギ' > char.normalize("NFC") 'ギ' > char.normalize("NFKD") 'ギ' > char.normalize("NFKD").length 2 > char.normalize("NFKC") 'ギ' > char.normalize("NFKC").length 1 - エンジニアリング
SPACEという生産性のためのフレームワーク
SPACEという生産性のためのフレームワークを知った。
生産性のフレームワークは有名所だとFour Keysがあるが、SPACEは下記の5つの指標で構成されている。
- Satisfaction and well being
- 開発者が自分の仕事、チーム、ツール、文化にどれだけ満足しているか
- ストレスチェックや、開発者が必要なツール・リソースを持っているか、
- Performance
- 開発者が書いたコードは、想定されたことを確実に実行したか?
- 品質や信頼性、定量的に見るならFour Keysにおける変更障害率あたり
- Activity
- 業務を遂行する過程で完了した行動やアウトプットの数
- 論文内では設計ドキュメント・仕様、PR、コミット、レビュー数となっている。Four Keysのデプロイ数が当てはまりそう
- Communication and collaboration
- メンバーやチームがどのようにコミュニケーションをとり、協力し合うか
- 論文内では、ドキュメントのみつけやすさや、レビューの質、コミュニケーションのネットワークメトリクスやオンボーディング時間が書かれている
- Efficiency and flow
- チームやシステム全体で中断や遅延を最小限に抑え、作業を完成、進行できているか
- Four Keysにおけるサービス復元時間・変更のリードタイムあたりが当てはまりそう
Four Keysと比べると、人の満足度、コミュニケーション的な部分が加わっている印象。
システムの健全さを表す指標がFour Keysなら、チームの健全さを表す指標がSPACEなのかな、と感じた。ちなみにForu KeysやこのSAPCEをまとめて DPE(Developer Productivity Engineering) と呼ぶこともあるらしい。
- Satisfaction and well being
- javascript
JavaScriptにおける剰余の正負
JavaScriptにおける剰余の正負の結果を毎回忘れる。 常に被除数と同一 と覚えればいいと学んだ。
被除数はすなわち「割られる数」でありa % bにおいてaである。$ node Welcome to Node.js v20.5.0. Type ".help" for more information. > 17 % 7 3 > 17 % - 7 3 > -17 % 7 -3 > -17 % -7 -3Wikipediaに言語ごとにまとまっていて非常に良かった。
- typescript
VSCodeにおいてTypeScriptの自動インポート対象から省きたい場合
autoImportFileExcludePatternsというフラグがある。これを設定することで、自動インポートの対象から省かれDX(Developer eXperience)が向上する。例えば、
Userというよくあるクラス名は既存のライブラリからもExportされていることが多い(SentryやDataDogなど)。
これらを指定すればそれらのライブラリからの自動インポートを省いてくれる。弱点としてはVSCodeにしか対応していない(正確に言えばTS Serverのオプションなので設定さえすればVimとかでも問題ないとは思う)のと、ライブラリごと省かれてしまうこと。
どうしても回避したいなら独自のTS Language Server Pluginを書けば良いと思うが…。ちなみにTypeScript4.8以降の機能。
https://devblogs.microsoft.com/typescript/announcing-typescript-4-8-rc/#exclude-specific-files-from-auto-imports - データ構造/アルゴリズム
Trieというデータ構造
文字列検索の文脈でTrie(トライ)というデータ構造を知った。
retrievalから取られたようだ。
検索文字列の辞書がある場合、その辞書の長さに関わらず一定のオーダーで検索できるのが強みらしい。 - Next.js
Next.jsでMDXを使う
画像周りが正直面倒くさ過ぎたため、MDXでなんとかできれば嬉しい。
内部的にはremarkを使っているらしい。ちなみに昔僕が使おうとしていたのはmarkedで、現在使っているのがmarkdown-it。https://nextjs.org/docs/pages/building-your-application/configuring/mdx
- ライフハック
VSCode上でGithubのPermalinkを取得する
選択範囲に対して、行番号を右クリックすることで、Permalinkが取得できる。
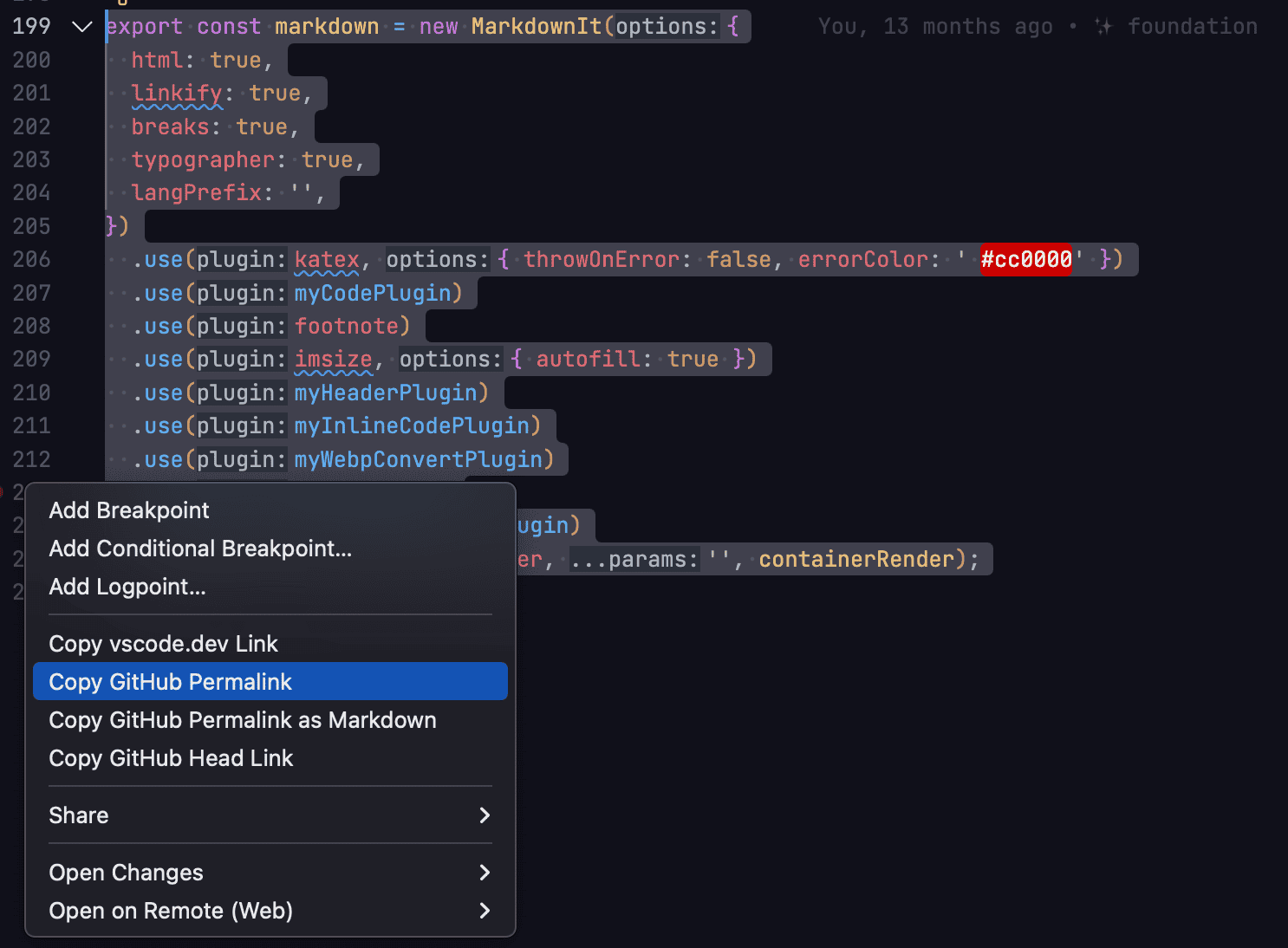
- ライフハック
TIL
TILはToday I Learnedの略で、今日学んだことを振り返る意味がある。
GithubにTILリポジトリを作り、Markdownか何かを作るフレームワーク的なものが広がったらしい。Slackのtimesチャンネルによく「こんなのあるんだ」的なのを呟いていたが、振り返りづらすぎるため、僕のBlogサービスにTIL的な機能を載っけてみる。
ほぼブログみたいなもんだが、もうちょい腰を据えずに自分向けの記事を書いていくつもり。
言葉の向こうに世界を見る
ライトモードへ
TIL


